Open Source Python PDF-metadatabibliotheek
Gratis en open source Python-bibliotheek om metagegevens van PDF-documenten te lezen en bij te werken.
Wat is pypdf?
Pypdf is een veelzijdige open source python bibliotheek die bekend staat om zijn diverse set aan functies voor PDF manipulatie. Deze bibliotheek is handig voor verschillende PDF manipulaties zoals PDF parsing en PDF splitting & merging etc. maar in deze product review zullen we ons alleen richten op de PDF metadata management functies.
Hieronder staan de belangrijkste kenmerken van pypdf met betrekking tot metadata:
- PDF-metagegevens lezen: Met pypdf kunt u eigenschappen (zoals auteur, maker, producent, titel, onderwerp en trefwoorden) van PDF-documenten lezen.
- PDF-metagegevens bijwerken: U kunt ook metagegevens van PDF-documenten bijwerken met behulp van pypdf.

Aan de slag met pypdf
Je hebt Python versie 3.6.0 of hoger nodig om pypdf te installeren en gebruiken. Installeer dus eerst Python en gebruik dan onderstaande commando's om pypdf op je machine te installeren met pip en virtual environment.
Linux
python3 -m venv venv
source venv/bin/activate
pip install pypdf
MacOS
python -m venv venv
source venv/bin/activate
pip install pypdf
Vensters
python3 -m venv venv
venv\Scripts\activate.bat
pip install pypdf
Metadata van PDF lezen
We kunnen de metadata van een PDF-document lezen met behulp van de pypdf-bibliotheek. We halen de metadata van een PDF op uit de metadata-eigenschap van de PdfReader-klasse in de pypdf-bibliotheek. Bekijk het onderstaande codefragment voor meer informatie:
Uitvoer
De onderstaande schermafbeelding toont de metagegevens van het meegeleverde PDF-bestand:
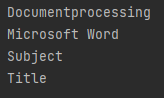
Metagegevens van PDF bijwerken
We kunnen ook metadata van een PDF-document bijwerken, zoals auteur, producent, onderwerp en titel, etc. met behulp van de pypdf-bibliotheek. We geven een object met de metadata-informatie door aan de add_metadata-methode van de PdfWriter-klasse in de pypdf-bibliotheek om metadata van het PDF-document bij te werken/schrijven. Bekijk voor meer informatie het onderstaande codefragment:
Conclusie
Concluderend blijkt pypdf een uitzonderlijke Python-bibliotheek te zijn voor het lezen en updaten van metadata van PDF-documenten. Ontwikkelaars kunnen metadata van PDF-documenten eenvoudig lezen en updaten zonder problemen.
Vergelijkbare Producten
- hachoir | Open Source Python-bibliotheek voor documentmetagegevens
- Mutagen Python-bibliotheek - Beheer moeiteloos audiometagegevens
- OpenPyXL API - Excel-metagegevens moeiteloos beheren
- pdf-lib voor JavaScript | PDF-metagegevens eenvoudig beheren
- PikePDF Python-bibliotheek - Moeiteloze PDF-manipulatie en beveiliging