Biblioteka metadanych PDF Pythona Open Source
Darmowa i otwartoźródłowa biblioteka języka Python do odczytu i aktualizowania metadanych dokumentów PDF.
Czym jest pypdf?
Pypdf to wszechstronna biblioteka open source w Pythonie, znana z różnorodnego zestawu funkcji do manipulacji plikami PDF. Ta biblioteka przydaje się do różnych manipulacji plikami PDF, takich jak parsowanie plików PDF i dzielenie i scalanie plików PDF itp., ale w tej recenzji produktu skupimy się tylko na funkcjach zarządzania metadanymi PDF.
Poniżej przedstawiono główne cechy języka pypdf związane z metadanymi:
- Odczyt metadanych PDF: Możesz odczytać właściwości (takie jak autor, twórca, producent, tytuł, temat i słowa kluczowe) dokumentów PDF za pomocą pypdf.
- Aktualizacja metadanych PDF: Możesz również aktualizować metadane dokumentów PDF za pomocą pypdf.

Pierwsze kroki z pypdf
Potrzebujesz wersji Pythona 3.6.0 lub nowszej, aby zainstalować i używać pypdf. Więc najpierw zainstaluj Python, a następnie użyj poniższych poleceń, aby zainstalować pypdf na swoim komputerze, używając pip i środowiska wirtualnego.
Linux
python3 -m venv venv
source venv/bin/activate
pip install pypdf
macOS
python -m venv venv
source venv/bin/activate
pip install pypdf
Okna
python3 -m venv venv
venv\Scripts\activate.bat
pip install pypdf
Odczytywanie metadanych pliku PDF
Możemy odczytać metadane dokumentu PDF za pomocą biblioteki pypdf. Metadane pliku PDF otrzymamy z właściwości metadata klasy PdfReader w bibliotece pypdf. Sprawdź poniższy fragment kodu, aby uzyskać szczegóły:
Wyjście
Poniższy zrzut ekranu przedstawia metadane dostarczonego pliku PDF:
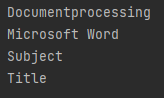
Aktualizowanie metadanych pliku PDF
Możemy również aktualizować metadane dokumentu PDF, takie jak autor, producent, temat i tytuł itp., używając biblioteki pypdf. Przekażemy obiekt zawierający informacje o metadanych do metody add_metadata klasy PdfWriter w bibliotece pypdf, aby zaktualizować/zapisać metadane dokumentu PDF. Aby uzyskać szczegółowe informacje, sprawdź poniższy fragment kodu:
Wniosek
Podsumowując, pypdf okazuje się wyjątkową biblioteką Pythona do odczytywania i aktualizowania metadanych dokumentów PDF. Programiści mogą łatwo odczytywać i aktualizować metadane dokumentów PDF bez żadnych problemów.
Podobne Produkty
- API OpenPyXL — bezproblemowe zarządzanie metadanymi programu Excel
- Biblioteka Mutagen Python — bezproblemowe zarządzanie metadanymi audio
- Biblioteka PikePDF Python — bezproblemowa manipulacja plikami PDF i bezpieczeństwo
- Biblioteka Pythona PyMuPDF dla metadanych PDF | Open Source
- hachoir | Biblioteka języka Python typu open source dla metadanych dokumentów