Thư viện siêu dữ liệu PDF Python nguồn mở
Thư viện Python mã nguồn mở và miễn phí để đọc và cập nhật siêu dữ liệu của tài liệu PDF.
Pypdf là gì?
Pypdf là một thư viện python mã nguồn mở đa năng được biết đến với bộ tính năng đa dạng để thao tác PDF. Thư viện này thực sự hữu ích cho nhiều thao tác PDF khác nhau như phân tích cú pháp PDF và chia tách & hợp nhất PDF v.v. nhưng trong bài đánh giá sản phẩm này, chúng tôi sẽ chỉ tập trung vào các tính năng quản lý siêu dữ liệu PDF của nó.
Sau đây là các tính năng chính của pypdf liên quan đến siêu dữ liệu:
- Đọc siêu dữ liệu PDF: Bạn có thể đọc các thuộc tính (như tác giả, người tạo, nhà sản xuất, tiêu đề, chủ đề và từ khóa) của tài liệu PDF bằng pypdf.
- Cập nhật siêu dữ liệu PDF: Bạn cũng có thể cập nhật siêu dữ liệu của tài liệu PDF bằng pypdf.

Bắt đầu với pypdf
Bạn cần Python phiên bản 3.6.0 trở lên để cài đặt và sử dụng pypdf. Vì vậy, trước tiên hãy cài đặt Python rồi sử dụng các lệnh bên dưới để cài đặt pypdf trên máy của bạn bằng pip và môi trường ảo.
Linux
python3 -m venv venv
source venv/bin/activate
pip install pypdf
Hệ điều hành MacOS
python -m venv venv
source venv/bin/activate
pip install pypdf
Cửa sổ
python3 -m venv venv
venv\Scripts\activate.bat
pip install pypdf
Đọc siêu dữ liệu của PDF
Chúng ta có thể đọc siêu dữ liệu của một tài liệu PDF bằng thư viện pypdf. Chúng ta sẽ lấy siêu dữ liệu của một PDF từ thuộc tính siêu dữ liệu của lớp PdfReader trong thư viện pypdf. Kiểm tra đoạn mã bên dưới để biết chi tiết:
Đầu ra
Ảnh chụp màn hình bên dưới hiển thị siêu dữ liệu của tệp PDF được cung cấp:
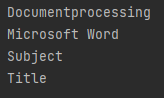
Cập nhật siêu dữ liệu của PDF
Chúng ta cũng có thể cập nhật siêu dữ liệu của một tài liệu PDF như tác giả, nhà sản xuất, chủ đề và tiêu đề, v.v. bằng cách sử dụng thư viện pypdf. Chúng ta sẽ truyền một đối tượng chứa thông tin siêu dữ liệu đến phương thức add_metadata của lớp PdfWriter trong thư viện pypdf để cập nhật/ghi siêu dữ liệu của tài liệu PDF. Để biết chi tiết, hãy kiểm tra đoạn mã bên dưới:
Phần kết luận
Tóm lại, pypdf chứng tỏ là một thư viện Python đặc biệt để đọc và cập nhật siêu dữ liệu của tài liệu PDF. Các nhà phát triển có thể dễ dàng đọc và cập nhật siêu dữ liệu của tài liệu PDF mà không gặp bất kỳ sự cố nào.